PinnedBarr MosesTop 10 Data & AI Trends for 2024From LLMs transforming the modern data stack to data observability for vector databases, here are my predictions for the top data…Jan 1822Jan 1822
Barr MosesinTowards Data ScienceMost Data Quality Initiatives Fail Before They Start. Here’s Why.Show me your data quality scorecard and I’ll tell you whether you will be successful a year from now.3d ago3d ago
Barr MosesSurvey Says: Data Quality Management Isn’t Evolving Fast Enough for AIEach year, Monte Carlo surveys real data professionals about the state of their data quality. This year, we turned our gaze to the shadow…Jun 254Jun 254
Barr MosesinTowards Data ScienceThe Past, Present, and Future of Data Quality Management: Understanding Testing, Monitoring, and…The data estate is evolving, and data quality management needs to evolve with it.May 251May 251
Barr MosesinTowards Data ScienceBuilding Ethical AI Starts with the Data Team — Here’s WhyGenAI is an ethical quagmire. What responsibility do data leaders have to navigate it? In this article, we consider the need for…Mar 203Mar 203
Barr MosesWhen a Data Mesh Doesn’t Make Sense for Your OrganizationData mesh requires the right mix of process, tooling, and internal resource to be effective. Find out what it takes to get data mesh-ready.Feb 267Feb 267
Barr MosesWill GenAI Replace Data Engineers? No — And Here’s Why.Wondering if GenAI will replace data engineers? You’re not alone. Learn why the answer is no, and what you can do to keep it that way.Feb 123Feb 123
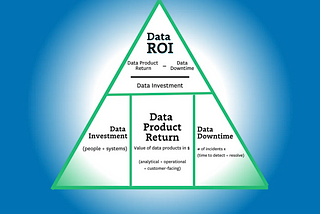
Barr MosesinTowards Data ScienceThe Data ROI Pyramid: A Method for Measuring & Maximizing Your Data TeamStruggling to articulate the value of your data team? Learn how to calculate your data team’s return with the Data ROI Pyramid.Feb 26Feb 26
Barr MosesinTowards Data Science5 Hard Truths About Generative AI for Technology LeadersGenAI that drives real business value takes real work. But it’s worth it.Jan 428Jan 428
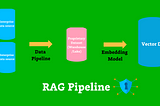
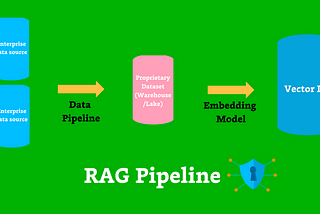
Barr MosesinTowards Data ScienceThe Moat for Enterprise AI is RAG + Fine Tuning — Here’s WhyHere’s why RAG and fine tuning pipelines are the only way enterprise AI succeeds — and how data trust is critical to their success.Nov 13, 20238Nov 13, 20238