When a Data Mesh Doesn’t Make Sense for Your Organization

Hype is a funny thing. Sometimes you find yourself in a Godfather Part 2 situation where the hype is totally justified. You hear about it. You try it. Life is changed. Hooray!
Other times, you find yourself in more of an Avatar: The Way of Water situation…where everyone around you is muttering things like “stunningly immersive,” and you’re on the sidelines wondering how much time you can spend watching blue aliens be bad at swimming.
And there are few data industry buzzwords that have been more hyped over the last four years than the self-service darling, “the data mesh.” Podcasts. Newsletters. Entire Slack groups dedicated to decentralized architecture. It was a lot.
Now, let me just say on the front end, the data mesh is not an Avatar 2 situation. (14 years, James. Ugh.) The data mesh is a thoughtful decentralized approach that facilitates the creation of domain-driven, self-service data products.
The problem is, not every organization should organize their architecture this way — or can support it.
Data mesh — including data mesh governance — requires the right mix of process, tooling, and internal resource to be effective. Whether by platform design or organizational structure, there are times when a data mesh won’t make sense for your business — and that’s alright!
But it begs the question — how do you know?
In this article, we’ll revisit data mesh to discuss what it is, why it makes sense for some teams, and when it doesn’t make sense for yours!
Hop on the hype cycle and let’s get rolling.
What’s a data mesh again?
Data access has been the cry of organizations for some time now. How do we get the data we need faster? How do we know what’s in it? How can we validate the accuracy and fitness of that data for our use cases?
And for a moment, data mesh was the preeminent answer to those questions.
Much in the same way that software engineering teams transitioned from monolithic applications to microservice architectures, the data mesh is, in many ways, the data platform version of microservices.
As first defined by Zhamak Dehghani in 2019, a data mesh is a decentralized approach that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design.
It consists of essentially four key components:
- Data-as-a-product — define the critical data assets including analytical, operational, and customer facing assets that are driving value for each domain
- Domain-oriented ownership — data ownership and their resulting data products are federated among domain owners including responsibility for their own ETL pipelines based on a unified set of capabilities.
- Self-service functionality — a data mesh allows users to abstract technical complexity and focus on self-serving their individual data use cases with a central platform that includes the data pipeline engines, storage, and streaming infrastructure.
- Interoperability and standardization — underlying each domain is a universal set of data standards that helps facilitate collaboration between domains with shared data, including formatting, data mesh governance, discoverability, and metadata fields, among other data features.
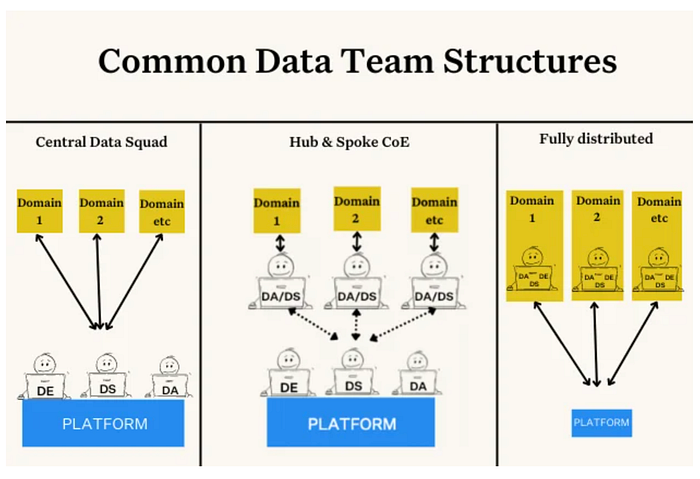
In real world deployments, this often translates into a small central platform team providing a shared infrastructure and baseline standards, that embedded data teams within each domain can build upon and customize for their needs.
But as the data mesh theory has peddled its way through the hype cycle, it’s become clear that the use case for a data mesh is far narrower than the concept initially suggested. And a lot more difficult.
So, as fantastically flexible as data mesh is — and we really do love it — below are a few times when a data mesh probably doesn’t make sense.
When data mesh doesn’t work:
Lack of domain talent density
Before you take the data mesh dive, you need to understand that implementing a successful democratization strategy isn’t for the faint of heart. One of the biggest reasons why data mesh initiatives are so frequently unsuccessful is due to the level of talent that’s required to make them work.
While the primary objective of the data mesh is to federate product ownership across domains, that only works if the domain team in question knows what to do with those data responsibilities once they get them.
Even with all its abstracted technical complexity, a data mesh still requires enough data talent embedded within each domain to make it work. Without the experience at the helm, your data mesh will be plagued with low quality, poorly maintained data products that will eventually need to be rebuilt anyway.
So, before your data team jumps head-first into a data mesh project, take a minute to consider the context of your organization. Does each domain team have the skill and competence to be successful? If not, what would it take to get them there? And will you have the buy-in from domain stakeholders to facilitate that change?
If the answer to those questions is “no” or “not any time soon,” don’t be ashamed to skip the data mesh for now and circle back when your organization is better equipped to realize its value.
Business domains have overlapping product needs
Another time a data mesh might not make sense is when your data products overlap across business domains.
Whether it’s a shared revenue dashboard or an operational ML model that’s being leveraged to external users, shared data products pose an interesting organizational quandary for democratized architecture.
Like Sisterhood of the Travelling Pants without the crowd appeal.
Again, the primary conceit of the data mesh is democratized ownership. So, if you can’t draw a clear line to the owner of a data product, how do you decide who gets the golden ticket? (Mixing metaphors a bit.)
When it comes to overlapping data products, you basically have two options.
- Option 1: Design data domains independently of business domains. While this is absolutely a viable option as long as the rest of your “to data mesh or not to data mesh” soliloquy works out, it’s likely to create a few organizational headaches as well — at least during the onboarding stages of the program.
- Option 2: Continue to manage those data products from a central data team. This can be accomplished by either maintaining a fully-centralized architecture or by simply managing those individual data products under a central data team — although the latter is still likely to create some organizational headaches in the process.
Additionally, our friends over at Sanne Group assigned data stewards to manage their shared data assets. While the idea of a data steward has fallen out of vogue somewhat over the years, this is a great example of augmenting data mesh for a given use case.
But again, if you aren’t sure how to answer this question, consider maintaining a centralized architecture for the time being and revisit the data mesh discussion at a later date.
Your data org is too small
There’s nothing wrong with being small. In fact, being a small org often means greater agility, more control, and the ability to iterate more efficiently.
But it also means that a data mesh might not be the most pragmatic initiative for the near term.
A move toward decentralization too soon may seem like a great idea on the surface. You might be thinking, “if I launch a data mesh early, I can build ownership into the culture now and avoid the messiness of adapting a larger organization later!”
Unfortunately, what you’re more likely to find is that’s actually just a lot more trouble than it’s worth.
First, building a data mesh is expensive — not just to your budget, but to the critical engineering time of the data team responsible for facilitating the change. And that’s an expense that’s difficult to justify in the face of a fledgling data team’s more primordial priorities — like delivering critical data products and establishing quality standards.
You need basic features and infrastructure to manage first before you can start thinking about the architecture that will enable them.
A data mesh will require months of dedicated planning, scoping, building, and training just to get it off the ground — and that’s assuming you’ve got enough budget on hand to pay for it.
Instead of spinning your wheels to keep pace with the hype train, spend your resources delivering early value instead with features and data products that solve new business use cases for your stakeholders.
What’s more, it’s not uncommon for larger organizations who’ve democratized data ownership to complain that they’ve become too decentralized and that their democratization has actually created new silos that make it difficult to unify and leverage data across the organization — one of the key components a data mesh is intended to deliver.
Generally, small orgs have small data needs. And if you can easily maintain centralized control (without sacrificing business value), you probably should. It’s always easier to enforce governance and quality standards across one team than five — and with less infrastructure weighing you (and your budget) down.
When you’re a lean team, opt for lean solutions. Start with a centralized ownership structure, and ride that train to its final stop. And then purchase a ticket for the democratization train.
You have a fragmented data platform

Recall that one of the critical aspects of a data mesh is standardization and interoperability.
The primary reason that a data mesh enables centralized data teams to release control of their data products is because they still control the infrastructure that supports them. That means that in order for platform teams to effectively regulate a data mesh and enable data to be shared across teams, each domain needs to be operating on a single platform with standardized tooling and data mesh governance practices.
If your platform tooling is fragmented — the marketing team choosing a “special” ETL tool, the finance team selecting their preferred BI solution — you’ve lost the data mesh battle before it’s even started.
So, priority number one is defining a “golden pathway” for how your data products should be built and then pressure testing that process as much as possible with a centralized data team before you think about federating ownership across domains.
And remember: A data mesh is more about the process than it is the tooling. If you don’t have the power to affect the culture that will carry out those processes, then defining the right tooling won’t help either.
Every reliable data architecture needs reliable data
Sometimes the answer to the data mesh is less of a “no” and more of a “not right now.” If you’re really set on pursuing a self-serve architecture, start small. Identify a specific area of your organization with clearly defined data products and controlled pipelines, and try to enable just that one team first. See if you’re able to check off each of the issues on this list and still provide the level of value you’d expect from your data mesh project.
Tools like data lineage can help data leaders understand consumption patterns across their organization and help them transition toward a more decentralized structure.
It might be that you realize a centralized approach is the best solution for your team after all, and you double down on SLAs or better data products as opposed to enabling a self-service model.
But the best thing you can do for your data architecture — whether you choose to democratize or centralize — is to support your data products with high quality and reliable data.
Data observability is the right data quality solution for centralized and domain-oriented architectures alike.
With easy alert routing for product owners and stakeholders, powerful centralized tools to see the health of your entire platform at a glance — and complete data lineage to understand how your data is impacting your domains — data observability will provide the data quality coverage you need to deliver value at every stage of your platform.
